
When everything fails
TEST I was recently reading a blog post of a startup who was using AWS with RDS. They experienced a problem and needed to restore from backups but their last 4 backups were corrupted. In the end they lost 250.000 visitors in a timespan of 6 hours (total duration of downtime).
This brought up a case I had worked 2 years ago where several cascading failures occured, causing a RAID array to be lost
It all started on a Friday morning, our monitoring systems detected a predictive failure on a RAID 10 array running on a directly attached storage. The DAS held the client’s entire data - business documents, user profiles - in total nearly 2 TB. The storage had premium support and we arranged a delivery for a spare part the same day. Once the drive arrived on site, the customer’s on site IT support proceeded to swap the device albeit without telling anyone. The disks were hot-swappable and a similar procedure had been executed 2 weeks previously without any problems. The only difference was the in the previous case the drive had actually failed, whereas in the 2nd instance it was still running but predicted to fail.
Once the failing drive had been swapped, the Windows partition disappared completely, causing an alert to be generated. At the same time, users lost access to all documents. The RAID software clearly stated the virtual array had failed and needed to be re-created.
The client was using a replication software that would replicate in near time from their on-premise server (which had experienced the failure) to their backup server in the main datacenter. There was no data loss as the replication was realtime, e.g. not scheduled.
The disaster recovery plan at this stage indicated that the network shares (\on-prem\documents) would be point to the backup server via a DNS change. The first issue arrose in that the Group policies configuring the network shares were using the server name instead of an alias. While an alias (CNAME record) could easily be modidied in DNS, replacing the server’s IP would not be possible. As such, we first needed to modify the group policies to use an alias, and pointed it to the backup server.
While this allowed users to continue accessing their files, it was quickly visible that the performance was extremely bad. While the on-prem server was using 15K Fast-class disks, the backup server was using 10K SATA disks. Together with the latency introduced by accessing the files over a VPN instead of LAN, it made working with the network shares nearly impossible.
Once we had determined the RAID array was not recoverable we proceeded to invoke the 2nd step in the DR - seeding the data from the backup server to the on-prem server. This scenario had never been tested and the replication software needed nearly 20 hours to index the 2 TB of files before actually starting to seed the files.
It took another 32 hours for the 2 TB to finish copying across the VPN at which point we flipped the alias back to the on-prem server.
While waiting for the data to transfer we also started to look at the root cause. Why did a routine operation cause the RAID to fail? Once we looked at the firmware version used by the RAID controller we noticed it was old - it hadn’t been updated in at least 3 years. The release notes contained a fix for a bug in the storage controller firmware where if a drive that has not yet failed is removed, could lead to the controller locking up.
aws support describe-services --query "services[*].[code,name]" --region us-east-1
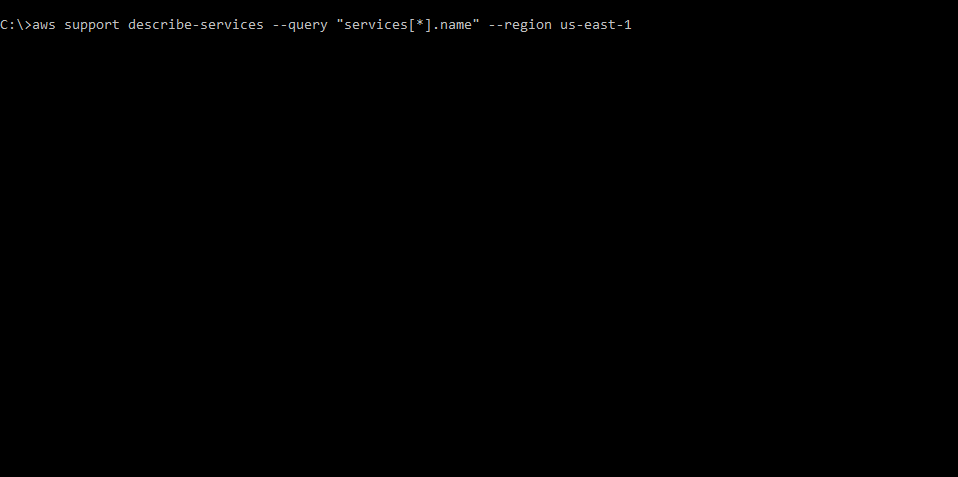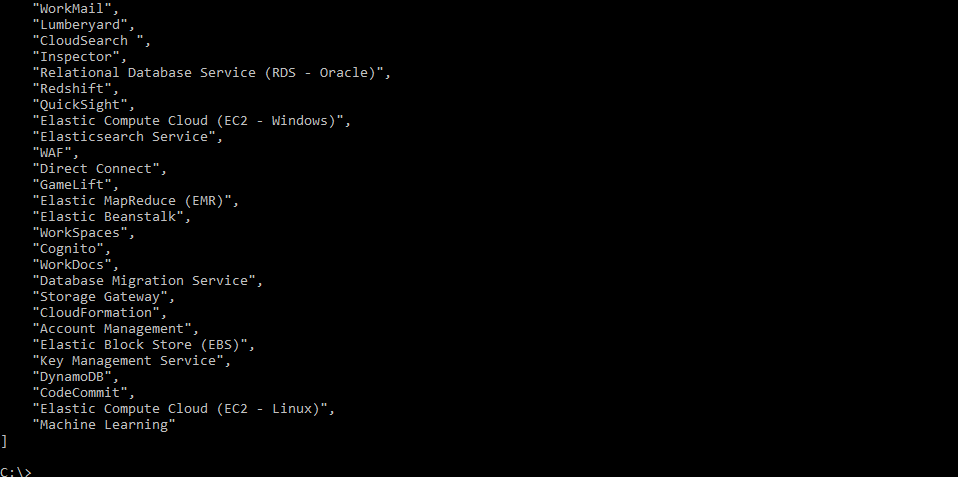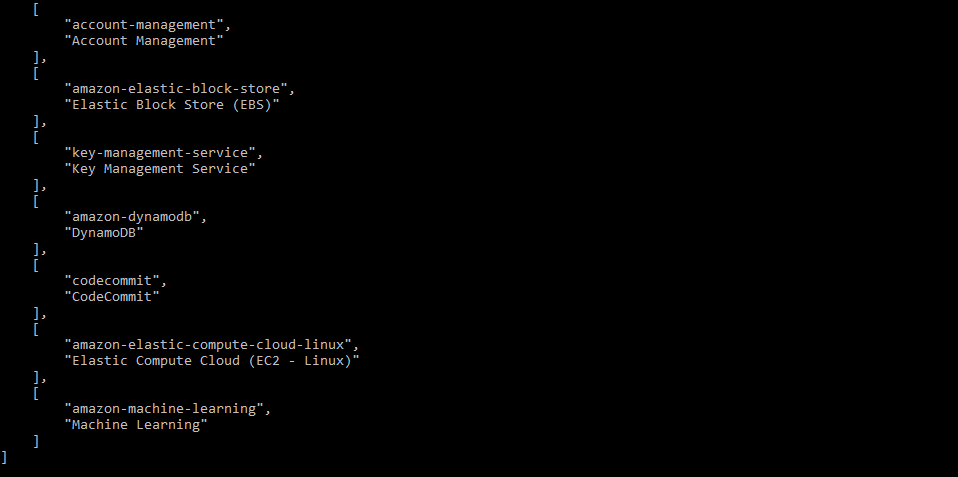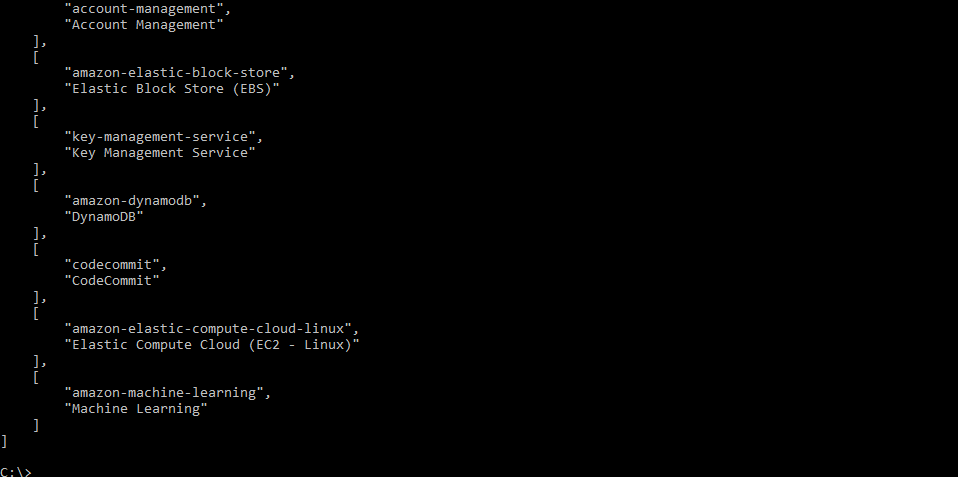
If you only want to get the names then run:
aws support describe-services --query "services[*].name" --region us-east-1
Note
I’m calling the API with the us-east-1 region since my default region is eu-west-1. The Support API has only 1 endpoint (us-east-1) and it needs to be specifically passed unless your default region is us-east-1.



